Архив по категории ‘программизм’.
18 апреля 2023, 09:34 дп
Обновил и во многом дополнил очередную статью из серии статей про использование библиотеки Matplotlib, предназначенной для построения графиков на Python.
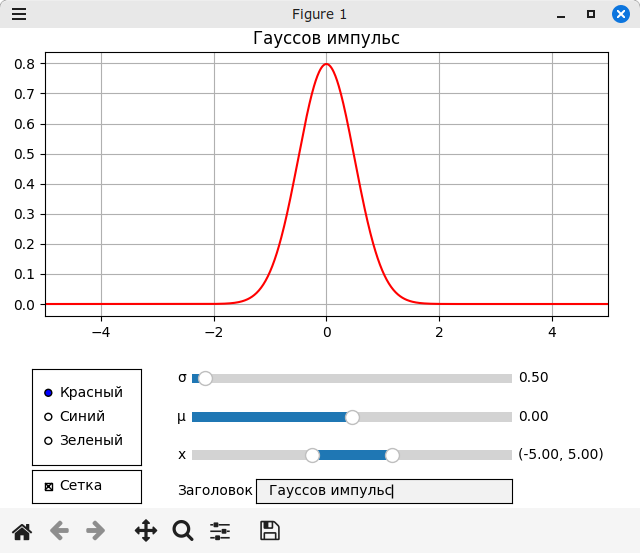
В этот раз обновлению подверглась статья Создание интерфейса средствами библиотеки Matplotlib, в которой рассказывается о том, как в окно с графиком можно добавить элементы управления (виджеты). В Matplotlib их не так много: кнопка, поле ввода, два вида ползунков, переключатели (radio buttons) и флажки (check buttons), но для многих задач этого будет достаточно, чтобы обойтись только библиотекой Matplotlib без сторонних библиотек для создания GUI.
Кстати, про внедрение графиков Matplotlib в интерфейс программы, написанной на wxPython у меня тоже была статья.

25 марта 2023, 06:12 пп
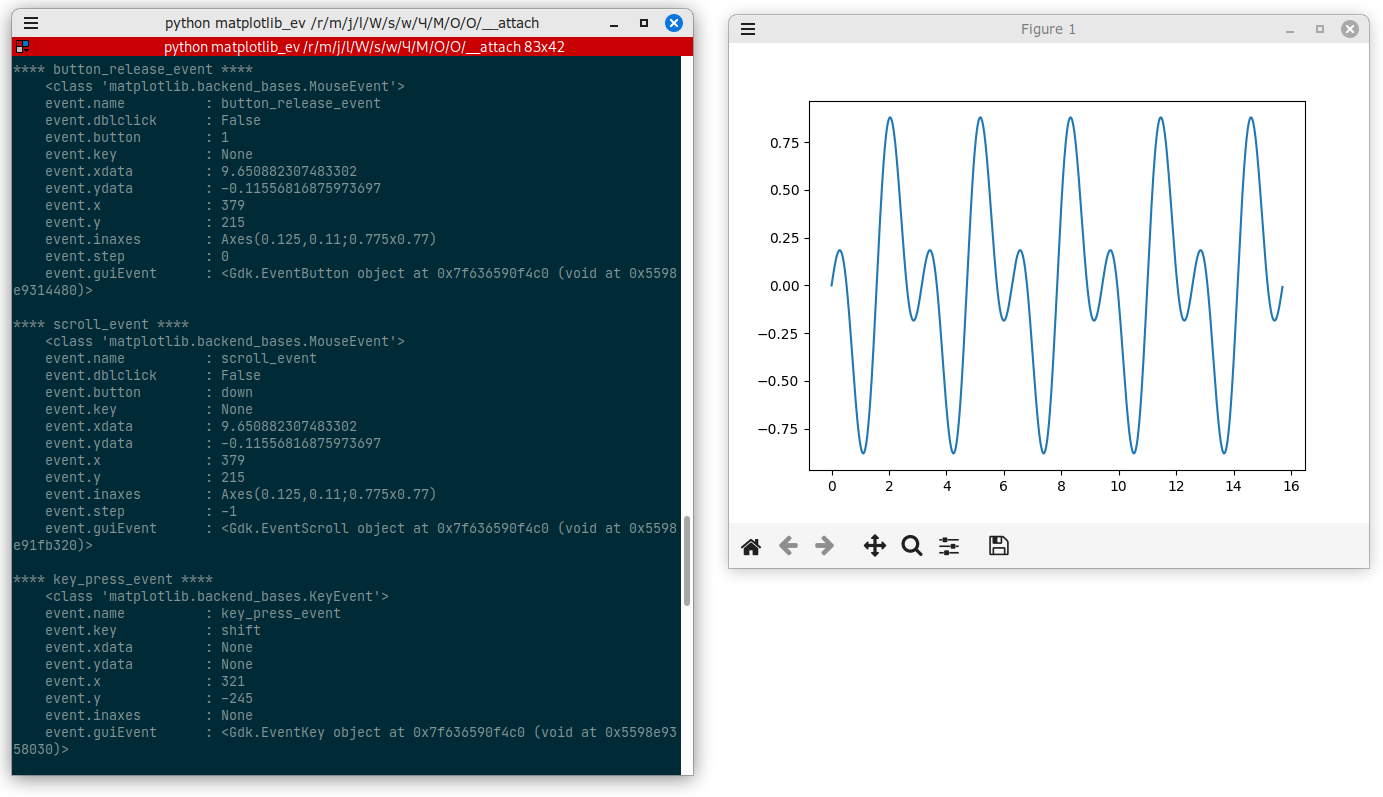
Очень неспешно продолжаю обновлять свои старые статьи про Matplotlib. Сегодня исправил статью Как обрабатывать события мыши и клавиатуры на графиках Matplotlib. Эта статья будет полезна, если вы захотите добавить немного интерактива для ваших графиков. Например, последний пример статье показывает, как можно добавлять на график метки с координатами (в системе координат осей), куда кликнул пользователь.
Дело близится к финалу, осталось поправить (читай, переписать) три статьи.
Полный список статей про Matplotlib можно найти на этой странице сайта.

25 февраля 2023, 11:38 дп
Продолжаю переписывать старые статьи про библиотеку Matplotlib, предназначенную для построения графиков на Python. Сегодня выложил обновленные статьи:

Обе эти статьи пришлось довольно сильно переписать, потому что писались они еще во времена Python 2. Теперь все примеры проверены на Python 3.10 и wxPython 4.2.0 (это касается первой статьи). Во второй статье добавлено побольше примеров, исправлены некоторые участки статьи, которые уже не актуальны в текущей версии Matplotlib и в современных версиях Windows.
Мне осталось переписать еще четыре старые статьи про Matplotlib, после чего можно будет приступать к написанию новых.
22 января 2023, 11:09 дп
Продолжаю обновлять давно написанные статьи про рисование графиков с помощью библиотеки Matplotlib.
Сегодня выложил очень сильно переписанную и дополненную статью Как изменять формат меток на осях. Под метками здесь понимаются числа, которые расположены вдоль осей около рисок и которые показывают значения отображаемой величины по каждой оси. В этой довольно большой статье написано, например, какие есть способы задавать формат чисел по осям, как добавлять единицы измерений к меткам, а заодно возложить на Matplotlib обязанность применять физические приставки вроде милли-, кило-, мега- и т.д. для представления величин. Описан простой способ нормирования данных и способ индивидуальной настройки каждой метки.
И заодно напомню, что список всех статей про Matplotlib можно найти на этой странице.
14 января 2023, 01:12 пп
После долгого перерыва продолжил обновлять, а во многом и переписывать, статьи про рисование графиков на языке Python c помощью библиотеки Matplotlib.
Сегодня выложил две обновленные статьи: Как изменять интервал осей и Как управлять положением рисок на осях. С ужасом заметил, что первоначальные статьи я писал больше 10 лет назад. Переписал исходники, чтобы они соответствовали более современному подходу в использовании этой библиотеки, заменил скриншоты, поправил текст, где-то добавил новые примеры.
10 января 2023, 11:45 пп
Сразу скажу, что вообще-то ГОСТы я уважаю. В инженерной деятельности, которой мы занимаемся на работе, при оформлении отчетов мы стараемся аккуратно следовать терминологии, которая прописана в стандартах. И тут я листаю сравнительно свежий ГОСТ 33707-2016 «Информационные технологии. Словарь» и вижу странное. А затем еще одно странное. И еще. В общем, решил я поделиться тем, что меня, мягко говоря, смутило. На самом деле к большинству терминов из этого стандарта у меня вопросов не возникло, а вот некоторые вызвали удивление.
Начнем сразу с козырей. Именно этот термин меня побудит написать этот пост.
Читать далее ‘Интересные находки в ГОСТ 33707-2016 «Информационные технологии. Словарь»’ »
9 января 2023, 09:57 дп
Давненько я не писал программерских статей на сайт. Написать эту статью меня подтолкнул перевод OutWiker на wxPython 4.2.0, когда оказалось, что в PyPi уже нет бинарных сборок под 32-разрядные Windows, а я пока не вижу причин отказываться от поддержки 32-битных операционок.
На самом деле сам процесс компиляции wxPython достаточно неплохо описан в документации, но есть некоторые моменты, связанные со сторонним софтом, который используется при сборке. И к тому же я попытался описать, что происходит на каждом шаге сборки, который нужно выполнить вручную, а также, что за библиотеки и софт требуется и зачем.
Ссылка на саму статью вот — Сборка библиотеки wxPython под Windows.
13 января 2022, 09:34 пп
Всем привет! После небольшого перерыва опять взялся за переписывание своих старых статей про библиотеку Matplotlib, предназначенную для построения графиков в Python.
В этот раз изменения коснулись следующих статей:
Ну и во всех примерах практически полностью переписал код и обновил скриншоты результатов работы скриптов.
4 декабря 2021, 01:45 пп
И снова всем привет!
За две недели, прошедшие с момента написания прошлого поста, перелопатил еще шесть статей про использование библиотеки Matplotlib.
- Как отображать формулы в нотации TeX
- Как выводить текст и настраивать его внешний вид
- Как использовать эффект рисования от руки
- Как рисовать стрелки на графиках и добавлять аннотации
- Как рисовать линии и геометрические фигуры на графике
- Как менять оформление линий по умолчанию
В этот раз изменения были не столь радикальные, как со статьями, которые переписывал в прошлый раз. Скорее всего это связано с тем, что эти статьи не настолько старые по сравнению с теми, которыми занимался в прошлые разы. В основном я поправлял стиль кода, что-то переписывал в более компактном виде, заменял использование модуля pylab на matplotlib.pyplot, обновлял скриншоты, вносил небольшие дополнения. Ну и еще выбросил несколько уже не актуальных разделов. Например, в одной из статей был раздел о том, как отображать текст с русскими буквами, но эта проблема уже давно решена в самой библиотеке.
5 ноября 2021, 06:52 пп
Всем привет!
Я продолжаю обновлять и дополнять свои старые статьи про Matplotlib, мощную библиотеку для Python, которая может рисовать различные типы графиков. В этот раз исправлению подверглись статьи:
Когда я начинал обновлять статьи, то я не ожидал, что по ходу дела мне захочется их так сильно переписывать и дополнять. Ну ладно, надеюсь, что какая-то польза от всего этого будет.